Transformer Architecture Explained: Attention is All You Need
🚀 Introduction
After understanding how Large Language Models (LLMs) generate text using next-token prediction, the next question is:
What architecture makes this possible?
The answer is the Transformer.
Introduced in the paper “Attention is All You Need”, the Transformer architecture fundamentally changed how we process sequential data and became the foundation of modern LLMs.
🧠 Why Not RNNs?
Before Transformers, models like RNNs processed data step by step. This made them:
- slow (no parallelization)
- weak at long-range dependencies
- difficult to scale
Transformers solved these problems by removing sequential processing and introducing a new mechanism: attention.
🏗️ High-Level Architecture
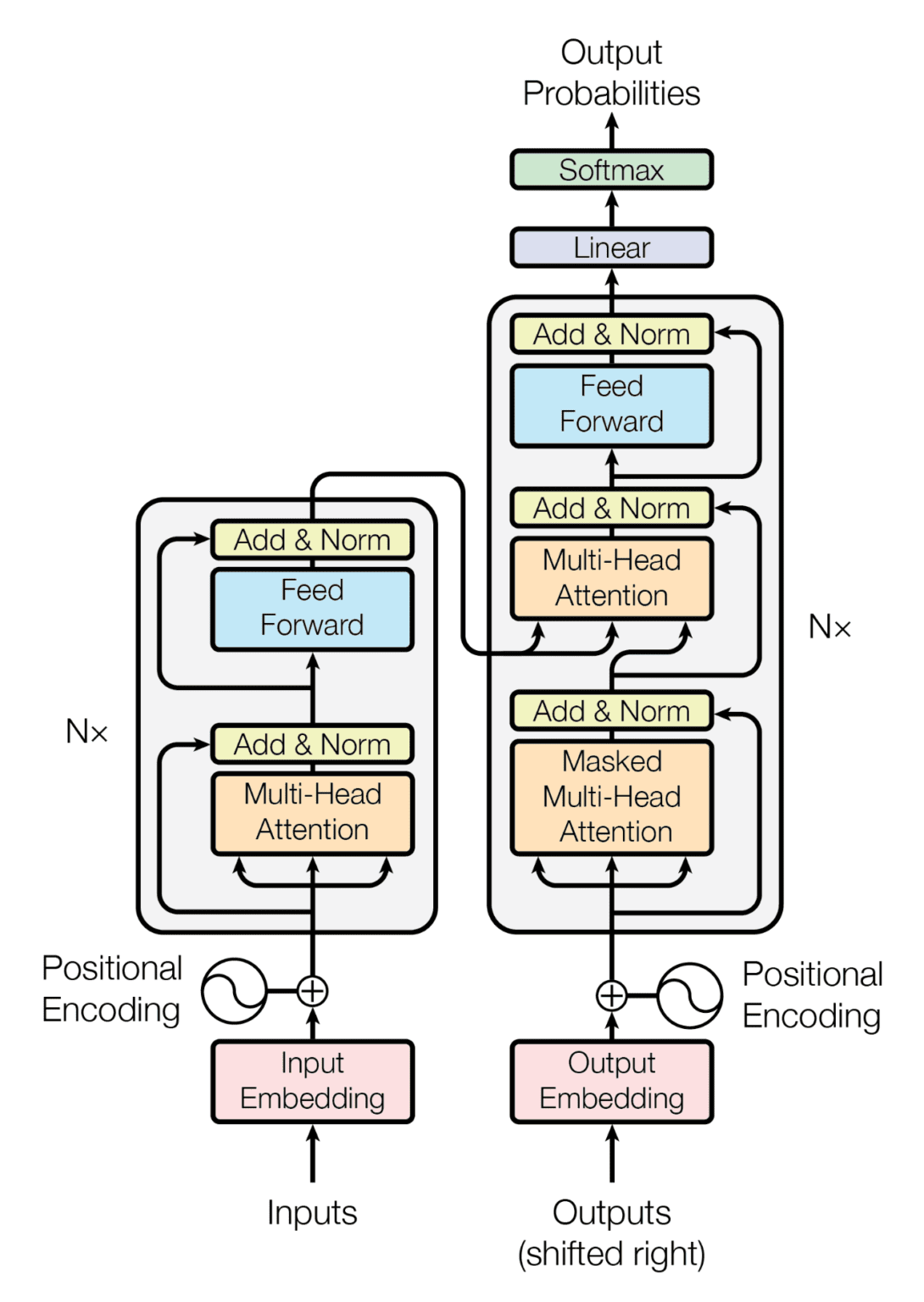
Source: Vaswani et al., 2017
A Transformer consists of two main components:
- Encoder
- Decoder
Each is built from multiple identical layers stacked on top of each other.
🔄 Encoder vs Decoder
Encoder
The encoder processes the input text and converts it into a contextual representation.
Decoder
The decoder takes this representation and generates output tokens step by step.
🔑 Attention Mechanism
The key innovation of Transformers is the attention mechanism.
Instead of processing words one by one, the model looks at all words in a sentence at the same time and decides:
Which words are important for understanding each token?
For example: “The cat sat on the mat”
To understand “sat”, the model focuses on “cat”.
⚡ Self-Attention
Self-attention allows each word to interact with every other word in the sequence.
This means:
- better context understanding
- long-range dependency handling
🧩 Positional Encoding
Since Transformers process all words at once, they need a way to understand word order.
This is done using positional encoding, which adds information about the position of each token in the sequence.
Without positional encoding:
- “dog bites man”
- “man bites dog”
would look the same to the model.
🔀 Multi-Head Attention
Instead of using a single attention mechanism, Transformers use multi-head attention.
This allows the model to:
- focus on different parts of the sentence simultaneously
- capture multiple relationships
For example:
- one head focuses on grammar
- another focuses on meaning
⚙️ Why Transformers Are Powerful
Transformers outperform older models because they:
- process data in parallel
- capture long-range dependencies
- scale efficiently with large datasets
- provide better context understanding
🎯 Conclusion
The Transformer architecture is the backbone of modern AI systems. By replacing sequential processing with attention mechanisms, it enables powerful and scalable language models.
Understanding Transformers is essential for working with LLMs, as almost all modern models are built on this architecture.
🚀 In the next post, we will explore Attention Mechanism and understand the differences between BERT, GPT, and other architectures.
Enjoy Reading This Article?
Here are some more articles you might like to read next: