Retrieval-Augmented Generation (RAG): Building Knowledge-Aware LLM Systems
🚀 Introduction
Large Language Models (LLMs) are powerful, but they have a fundamental limitation:
They are static.
Once trained, their knowledge is fixed. They cannot access new information unless retrained, and they may hallucinate when asked about unknown facts.
Retrieval-Augmented Generation (RAG) solves this problem by combining retrieval systems with generation models, allowing LLMs to access external knowledge dynamically.
In this post, we will explore RAG from an advanced, system-level perspective.
🧠 What is RAG?
RAG is a hybrid architecture that combines:
- A retriever → finds relevant documents
- A generator (LLM) → produces answers
Instead of relying solely on internal knowledge, the model retrieves relevant context and conditions its generation on that information.
🏗️ High-Level Architecture
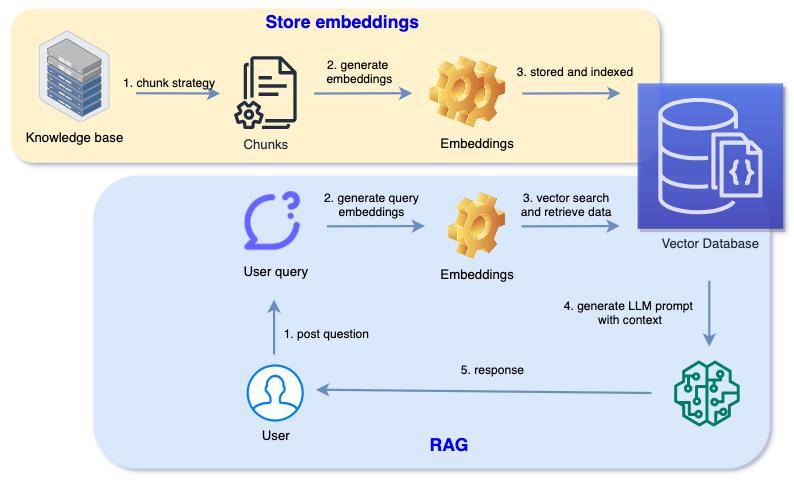
Source: Loh, S., "Making Sense of Vector Search and Embeddings", 2024
A typical RAG pipeline consists of:
- User query
- Embedding model
- Vector database retrieval
- Context injection
- LLM generation
🔑 Step 1: Embeddings
Before retrieval, text must be converted into numerical representations.
Embeddings map text into high-dimensional vector space where:
- similar meanings → close vectors
- different meanings → distant vectors
🔍 Step 2: Vector Search
The system retrieves relevant documents using similarity search:
- cosine similarity
- dot product
- Euclidean distance
The goal:
find the most relevant chunks of information
📚 Step 3: Chunking Strategy
Documents are split into smaller pieces (chunks).
Why?
- LLM context window is limited
- retrieval becomes more precise
Trade-offs:
- small chunks → precise but fragmented
- large chunks → more context but noisy
⚙️ Step 4: Context Injection
Retrieved documents are added to the prompt: Context: [retrieved documents]
Question: [user query]
The LLM now generates answers based on both:
- retrieved context
- internal knowledge
🤖 Step 5: Generation
The LLM uses the augmented prompt to generate an answer.
This reduces:
- hallucinations
- outdated knowledge
⚡ Why RAG Works
RAG improves LLM performance by:
- grounding responses in real data
- enabling up-to-date knowledge
- reducing hallucination risk
🧠 Dense vs Sparse Retrieval
Sparse Retrieval (BM25)
- keyword-based
- exact matching
Dense Retrieval (Embeddings)
- semantic similarity
- better generalization
Modern RAG systems use dense retrieval.
🧩 Vector Databases
Popular vector databases:
- FAISS
- Pinecone
- Weaviate
- Chroma
They enable efficient similarity search at scale.
🔥 Advanced RAG Concepts
🔹 Hybrid Search
Combine:
- keyword search
- vector search
🔹 Re-Ranking
Initial retrieval → re-ranked using a stronger model.
🔹 Multi-Hop Retrieval
Retrieve information in multiple steps.
🔹 Query Expansion
Rewrite query to improve retrieval quality.
⚠️ Limitations of RAG
RAG is powerful but not perfect:
- retrieval errors → bad answers
- context overflow
- latency (retrieval + generation)
- dependency on data quality
⚖️ RAG vs Fine-Tuning
| Approach | Strength | Weakness |
|---|---|---|
| Fine-Tuning | Deep adaptation | Expensive, static |
| RAG | Dynamic knowledge | Retrieval dependency |
🧠 When to Use RAG
Use RAG when:
- knowledge changes frequently
- external data is required
- hallucinations must be minimized
🔗 Real-World Example
Example: Company internal chatbot
Without RAG:
- model guesses answers
With RAG:
- retrieves company docs
- answers based on real data
⚙️ Full Pipeline (Advanced View)
- Data ingestion
- Cleaning & chunking
- Embedding generation
- Indexing in vector DB
- Query embedding
- Retrieval
- Prompt construction
- LLM inference
🎯 Conclusion
RAG is one of the most important techniques in modern AI systems.
It transforms LLMs from:
- static models
into:
- dynamic, knowledge-aware systems
🚀 In the next post, we will explore building a real RAG system step-by-step using Python and vector databases.
Enjoy Reading This Article?
Here are some more articles you might like to read next: