What is Generative AI? Types and Architectures
🚀 What is Generative AI?
Generative AI refers to artificial intelligence systems that can generate new content based on a given input. This content is not limited to text; it can also include images, audio, and even video. While traditional AI systems are typically designed to analyze or classify data, Generative AI goes one step further by producing entirely new outputs.
The best way to understand these systems is not as a single model, but as a collection of approaches tailored to different types of data. Text, images, and audio each present unique challenges, and therefore require different modeling techniques. For this reason, Generative AI is generally divided into three main categories:
- 📝 Text
- 🖼️ Image
- 🔊 Audio
Another important aspect of Generative AI systems is how they operate in two main phases: training and inference. During training, the model learns patterns from large datasets. During inference, it generates outputs based on user input. What we interact with in real-world applications is the inference phase.
📝 Text Generation
Text generation is one of the most common applications of Generative AI. The goal is to produce meaningful, coherent, and contextually relevant text based on a given input. This process is fundamentally tied to the sequential nature of language, where word order and relationships are crucial.
At its core, text generation relies on a simple but powerful idea: predicting the next most likely word. This approach, known as next-token prediction, allows models to generate text step by step, building sentences that appear natural and meaningful.
Before processing, text is converted into numerical representations called embeddings. These embeddings allow the model to capture semantic relationships between words and understand context more effectively.
Recurrent Neural Networks (RNN)
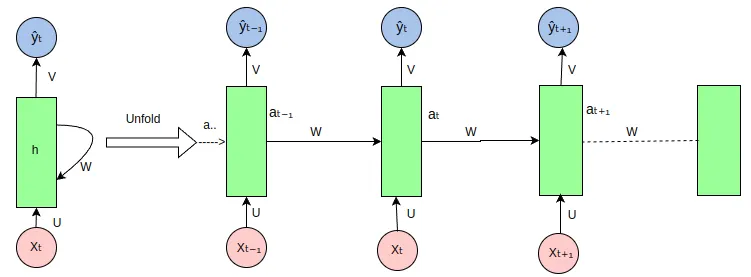
Source: Wikimedia Commons
One of the earliest architectures used for sequence modeling is the Recurrent Neural Network (RNN). RNNs are designed to process sequential data by incorporating information from previous steps. They achieve this by feeding their output back into the network as input for the next step, effectively creating a form of memory.
This makes RNNs suitable for tasks such as language modeling, speech recognition, and machine translation.
However, RNNs struggle with long-term dependencies. As sequences grow longer, the model finds it difficult to retain earlier information, which leads to performance degradation. This limitation, along with training challenges such as the vanishing gradient problem, reduced their effectiveness in large-scale applications.
Feedforward Neural Networks

Source: Wikimedia Commons
In contrast, feedforward neural networks process data in a single direction and do not retain information from previous steps. Because of this, they are not suitable for sequence-based tasks where context and order matter.
Transformers
The architecture that replaced RNNs in most modern applications is the Transformer. Unlike RNNs, transformers process the entire input sequence simultaneously rather than step by step.
This is made possible through the attention mechanism, which allows the model to identify which words are most important in a given context. As a result, transformers can capture relationships between words more effectively and handle long-range dependencies.
Additionally, transformers support parallel computation, making them faster and more scalable. This is why modern large language models (LLMs) are built on transformer architectures.
🖼️ Image Generation
Image generation is one of the most visually impressive applications of Generative AI. Creating realistic images from scratch requires models that can learn complex patterns in visual data.
Generative Adversarial Networks (GAN)
GANs consist of two competing models:
- A generator, which produces synthetic data
- A discriminator, which evaluates whether the data is real or fake
These two models are trained together in a competitive process. As the generator improves, it produces increasingly realistic images, while the discriminator becomes better at detecting them.
Diffusion Models
Diffusion models have recently become the dominant approach in image generation. These models work by gradually adding noise to an image and then learning how to reverse this process.
In other words, they learn how to generate meaningful images starting from pure noise. This method has proven highly effective in text-to-image systems and is currently considered state-of-the-art.
🔊 Audio Generation
Audio generation is another key area of Generative AI. Producing natural and realistic sound requires models that can capture temporal dependencies and frequency patterns.
Different architectures are used in this domain:
- Transformer-based models for text-to-speech
- Diffusion models for high-quality audio generation
- WaveNet for autoregressive audio synthesis
🧠 Generative AI for NLP
One of the most impactful applications of Generative AI is in Natural Language Processing (NLP). NLP focuses on enabling machines to understand and generate human language.
Applications include:
- Machine translation
- Text summarization
- Sentiment analysis
- Chatbots
Today, most of these systems rely on transformer-based architectures due to their ability to understand context and capture relationships within text.
🎯 Conclusion
Generative AI is not a single model or technique, but rather a collection of architectures designed for different types of data and problems.
- Text → Transformers
- Image → GANs and Diffusion Models
- Audio → Transformers and Diffusion Models