Encoder vs Decoder: Understanding BERT, GPT and Modern LLM Architectures
🚀 Introduction
After understanding how Transformers work and how attention mechanisms enable powerful language modeling, the next step is to understand how different model architectures are built on top of Transformers.
Not all Transformer-based models are the same. In fact, modern language models can be grouped into three main categories:
- Encoder-only models
- Decoder-only models
- Encoder-decoder models
These architectures form the foundation of models like BERT, GPT, and BART.
🧠 Encoder vs Decoder: The Core Difference
At a high level, the difference between encoder and decoder comes down to how they process and generate information.
- Encoder → reads and understands input
- Decoder → generates output
The encoder builds a rich representation of the input, while the decoder uses that representation (or previous tokens) to generate new tokens.
Source: Hoque, M. (Medium)
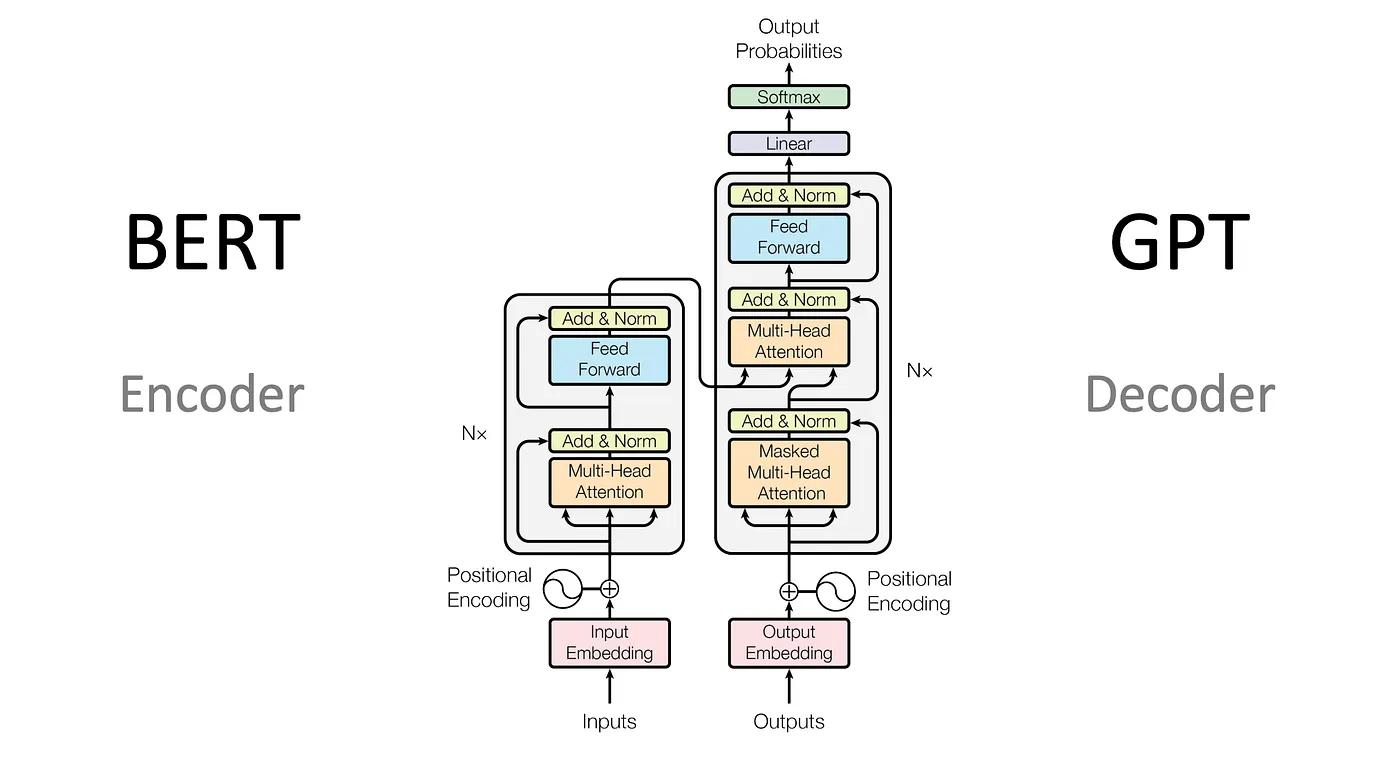
🔵 Encoder-Only Models (BERT)
Encoder-only models are designed for understanding tasks.
The most famous example is BERT (Bidirectional Encoder Representations from Transformers).
🧠 How BERT Works
BERT uses the encoder stack of the Transformer and processes the entire sentence at once using bidirectional context.
This means:
- each word looks at both left and right context
- deeper understanding of meaning
📊 What Makes BERT Special?
- Fully bidirectional
- Strong contextual understanding
- Not designed for text generation
🧪 Use Cases
- Text classification
- Sentiment analysis
- Question answering
- Named entity recognition
🔴 Decoder-Only Models (GPT)
Decoder-only models are designed for generation tasks.
The most well-known example is GPT (Generative Pre-trained Transformer).
🧠 How GPT Works
GPT generates text one token at a time using next-token prediction.
It uses:
- masked self-attention
- only previous tokens (left context)
📊 What Makes GPT Special?
- Autoregressive generation
- Can produce long coherent text
- Scales extremely well
🧪 Use Cases
- Chatbots
- Code generation
- Content generation
- Conversational AI
🟣 Encoder-Decoder Models (BART, T5)
Encoder-decoder models combine both components.
Examples:
- BART
- T5
🧠 How They Work
- Encoder processes input
- Decoder generates output
📊 What Makes Them Powerful?
- Combine understanding + generation
- Ideal for transformation tasks
🧪 Use Cases
- Machine translation
- Text summarization
- Paraphrasing
⚖️ Comparison of Architectures
| Architecture | Example | Strength | Use Case |
|---|---|---|---|
| Encoder-only | BERT | Understanding | Classification |
| Decoder-only | GPT | Generation | Text generation |
| Encoder-Decoder | BART | Both | Translation, summary |
⚡ Why This Matters
Understanding these architectures is critical because:
- Different tasks require different models
- Not all LLMs are designed for generation
- Choosing the right architecture impacts performance
🎯 Conclusion
Transformer-based models can be divided into three main categories:
- Encoder → understanding
- Decoder → generation
- Encoder-decoder → both
Models like BERT, GPT, and BART are built on these foundations, each optimized for different types of problems.
🚀 In the next post, we will explore Fine-Tuning vs Prompting vs RAG, and how to adapt LLMs to real-world applications.
Enjoy Reading This Article?
Here are some more articles you might like to read next: