A Deep Dive into Attention: Self-Attention, Multi-Head Attention and Positional Encoding
🚀 Introduction
Modern Large Language Models (LLMs) are built on Transformer architectures, and at the heart of Transformers lies one key idea: attention.
Before attention, models such as RNNs processed sequences step by step. This made it difficult to capture long-range dependencies and limited scalability. Attention changed this by allowing models to process entire sequences at once and dynamically focus on the most relevant parts of the input.
In this post, we will take a deep and comprehensive look at:
- Attention
- Self-Attention
- Multi-Head Attention
- Positional Encoding
🧠 What is Attention?
At its core, attention answers a simple question:
Which parts of the input are most important?
Instead of treating every word equally, the model assigns different importance scores to each token.

Source: Vig, J. (BertViz)
Consider the sentence: “The cat sat on the mat because it was tired”
To understand “it”, the model must focus on “cat”, not “mat”.
🔍 Query, Key, Value (QKV)
Attention is computed using three vectors:
- Query (Q) → what we are looking for
- Key (K) → what each word represents
- Value (V) → the actual information
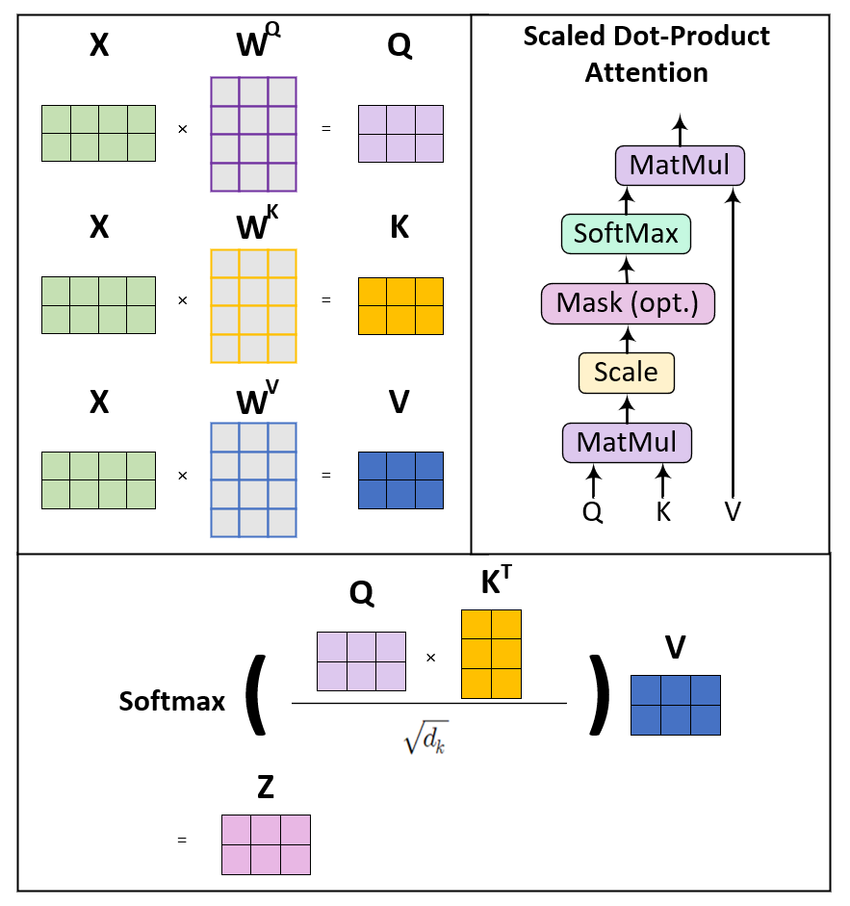
Source: ResearchGate (QKV Attention Diagram)
The model:
- Compares Query with Keys
- Computes similarity scores
- Applies softmax
- Uses scores to weight Values
This produces a context-aware representation.
🔁 Self-Attention
Self-attention allows each word to attend to all other words in the same sentence.
This enables:
- long-range dependency modeling
- better contextual understanding
- parallel computation
🔀 Multi-Head Attention
Instead of a single attention mechanism, Transformers use multiple attention heads.
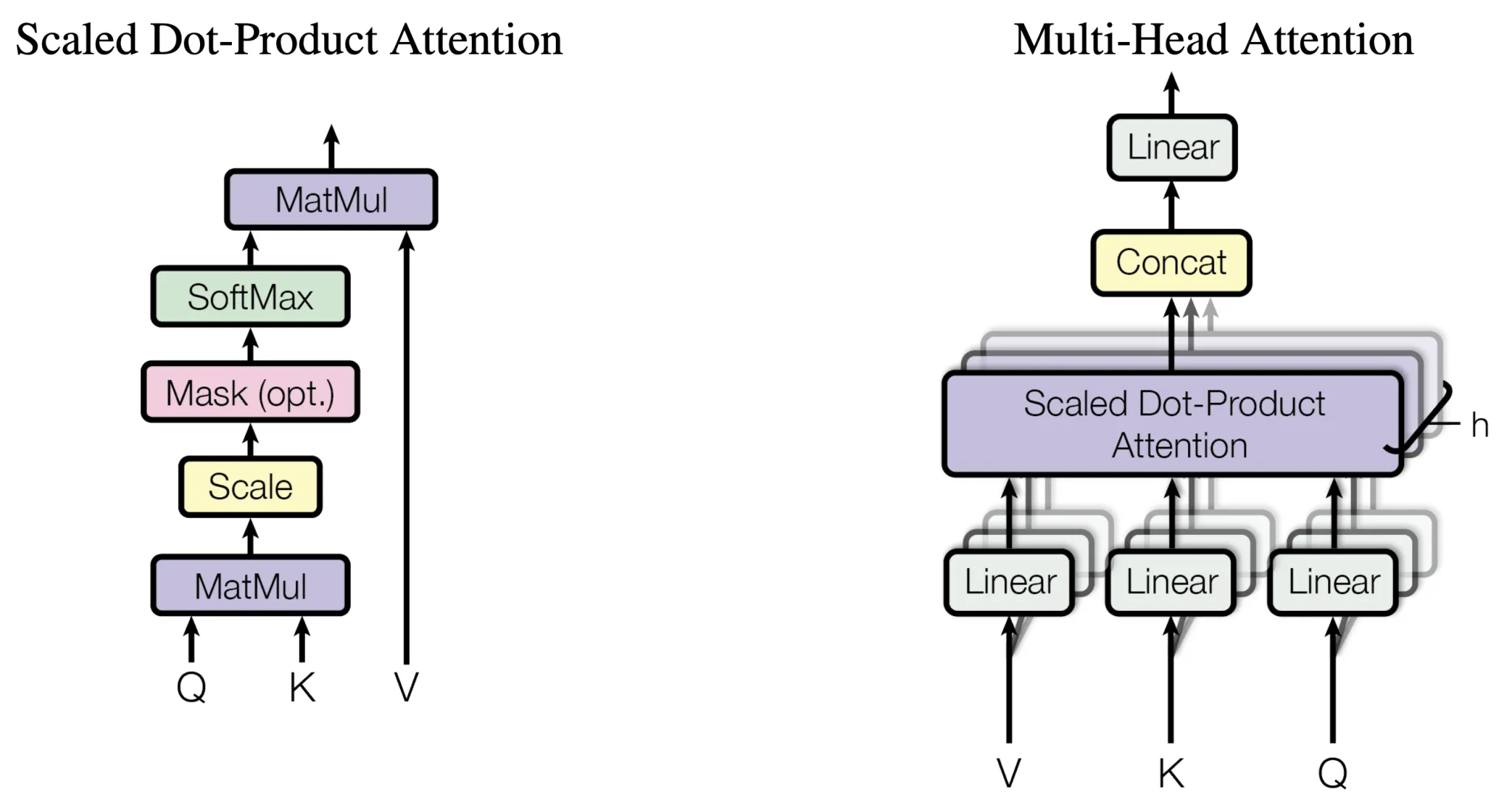
Source: AIML.com
Each head learns different relationships:
- syntax
- semantics
- position
Outputs are combined into a richer representation.
🧭 Positional Encoding
Transformers process all tokens simultaneously, so they need positional information.
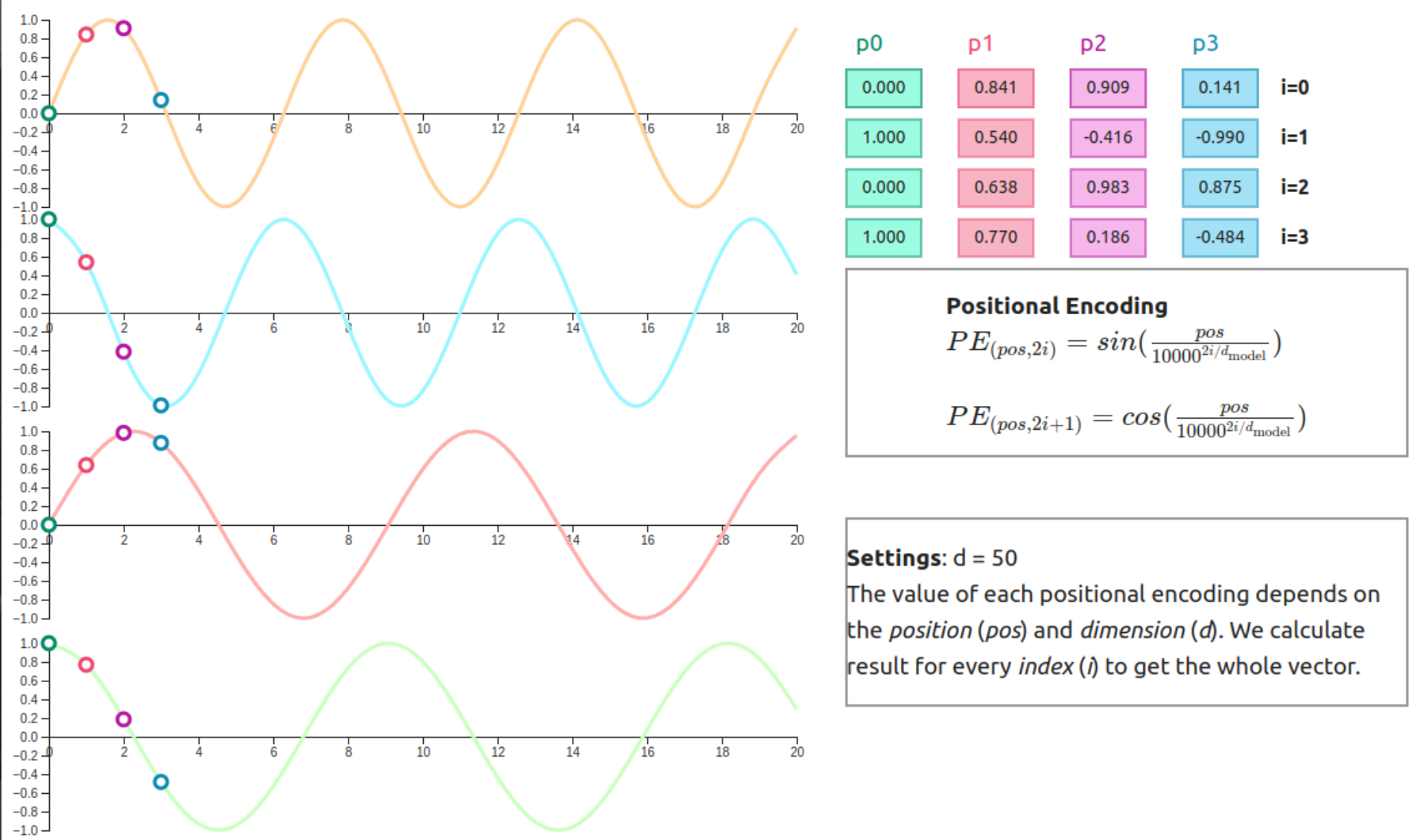
Source: Erdem, 2021
📐 Sinusoidal Encoding
\[PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d}}\right)\] \[PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d}}\right)\]This allows:
- encoding relative positions
- generalization to longer sequences
🔄 Learnable Positional Encoding
Instead of fixed functions, models can learn positional embeddings during training.
🧩 Segment Embeddings
Used in models like BERT:
- distinguish sentence A vs B
- useful for QA and classification
🔗 Putting Everything Together
- Tokens → embeddings
- Positional encoding added
- Self-attention computes relationships
- Multi-head attention enriches representation
⚡ Why This Changed Everything
Transformers:
- remove sequential bottlenecks
- scale efficiently
- capture global context
🎯 Conclusion
Attention is the foundation of modern AI.
- Attention → relevance
- Self-attention → full connectivity
- Multi-head → multiple perspectives
- Positional encoding → order
Together, they power modern LLMs.
🚀 In the next post, we will explore Encoder vs Decoder architectures and models like BERT, GPT, and BART.
Enjoy Reading This Article?
Here are some more articles you might like to read next: